Processo de Subida dos Dados
Visão geral
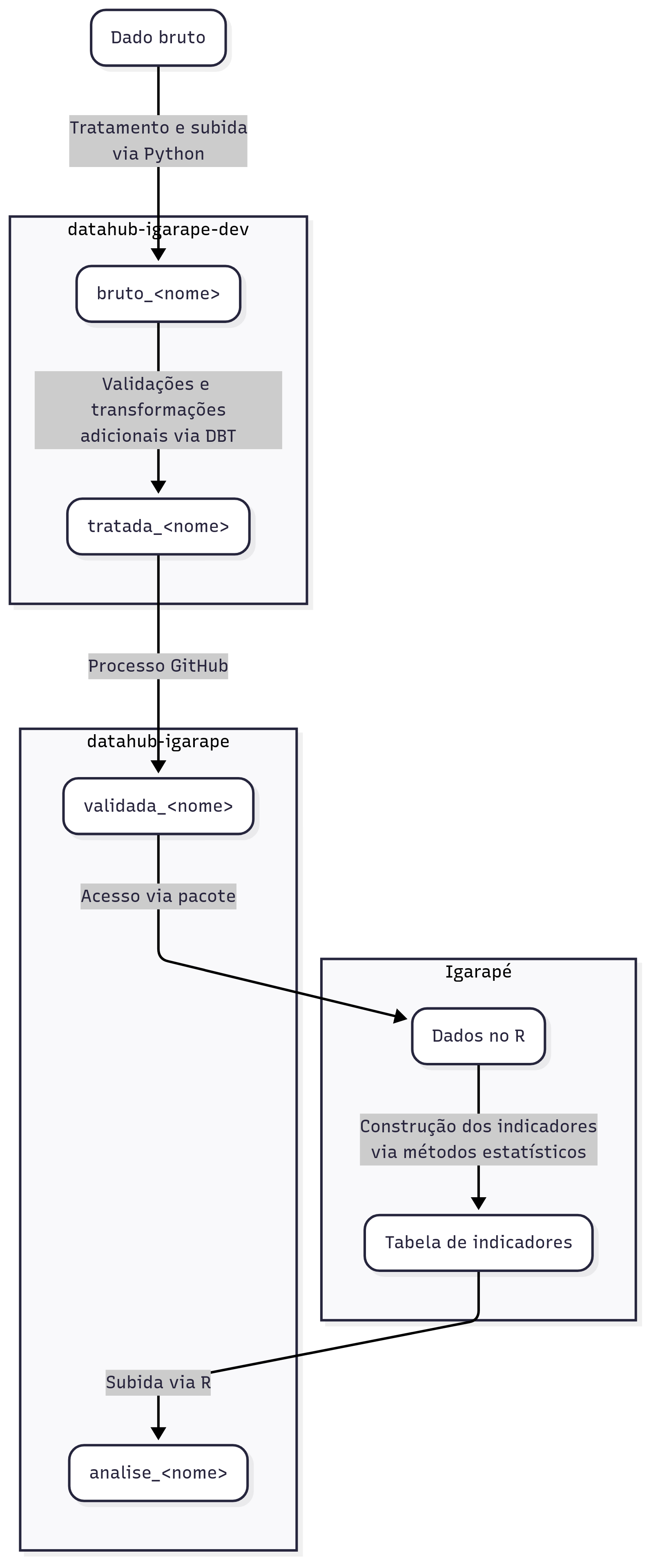
Este documento descreve o processo de dados. Isto é, da ingestão do dado bruto a criação das tabelas finais utilizadas para produtos de dados. O schema abaixo representa as etapas em alto nível, da ingestão a aplicação dos dados, que serão discutidas nessa seção.
O repositório de hospedagem de código
O repositório datalake-2025 abriga todo o código de Coleta e Tratamento das tabelas que compõem o Datahub
Ops... Tentei acessar o link do repositório e a página não foi encontrada
Para visualizar o repositório no Github é preciso solicitar acesso para o gestor de repositórios do Igarapé. Como o repositório é privado, é necessário que a configuração seja feita.
A infraestrutura
Na seção de visão geral da infra apresentamos os componentes da infraestrutura, suas funcionalidades e usos ao longo do processo de dados. É importante ter domínio da infraestrutura apresentada para compreender o processo de dados.
Estrutura de pastas
Cada dataset tem uma subpasta com respectivo nome, dentro da pasta models, no repositório datalake-2025.
Cada pasta de dataset obedece a uma estrutura que inclui:
a. uma subpasta architecture com as arquiteturas de todas as tabelas do dataset;
b. uma subpasta code onde estão armazenados os scripts, arquivos de constantes, arquivos auxiliares, geralmente seguindo a estrutura;
c. arquivos para o dbt (schema.yml e o arquivo SQL de materialização da tabela no BigQuery).
datalake-2025/ ├── models/ │ ├── nome_dataset/ │ │ ├── architecture/ # diagramas ou definições de arquitetura │ │ ├── code/ # scripts de apoio │ │ │ ├── constants.py # variáveis necessárias para rodar o scrip principal │ │ │ └── script_principal.py # script que captura dados e inclui eles na infraestrutura do datalake │ │ ├── nome_dataset__nome_tabela.sql # modelo SQL dbt │ │ └── schema.yml # configuração de esquema dbt │ └── [...] # outros datasets ├── [...] # outros diretórios do projeto
Fluxo dos dados no datalake
Como vimos na seção visão geral da infraestrutura, o processo de dados ocorre em 3 etapas principais: ingestão, transformação e disponibilização de dados para aplicações. Com base nestas categorias, explicaremos o passo a passo do processo desenhado para o DataHub do Instituto Igarapé.
Tabela de Arquitetura
Esta é uma etapa importante do processo que precede a ingestão. Fazemos um mapeamento do schema dos dados e definimos um modelo de normalização que será utilizado nas etapas de transformação. Mais detalhes sobre a tabela de arquitetura
ETAPA 1: Ingestão de Dados
Objetivo: Capturar dados brutos de fontes externas e armazená-los na infraestrutura do DataHub
A ingestão dos dados ocorre através da construção de códigos de coleta semi-automatizados que ficam registrados no repositório datalake-2025. O objetivo é coletar dados de fontes externas variadas e disponibilizá-los para processamento.
🔧 Processo Técnico:
1. Scripts Python semi-automatizados capturam o dado da fonte externa e realiza alguns pequenos tratamentos
2. O pacote datahub salva esses dados no bucket do Google Cloud Storage
3. O pacote datahub cria no projeto igarape-datahub-dev com prefixo brutos_ um conjunto de dados com as tabelas
4. O pacote datahub configura uma tabela externa conectando Storage ao BigQuery
🔔 Dados Não Validados
Todos os conjuntos de dados com prefixo brutos_ são dados que não passaram por processos de padronização e validação. Representam os dados brutos na infraestrutura do DataHub e ainda serão processados nas etapas seguintes.
Todas essas operações ocorrem no projeto da GCP igarape-datahub-dev
ETAPA 2: Padronização
Objetivo: Padronizar, limpar e validar dados conforme manual de estilo
Nesta etapa, o DBT (Data Build Tool) entra em cena para aplicar processos de padronização em acordo com o Manual de Estilo e executar testes de validação
📚 Padrões de Nomenclatura
Os padrões de nomenclatura de conjuntos de dados estão definidos no Manual de Estilo.
Desenvolvimento da Transformação
- Input: Tabelas de conjuntos de dados com prefixo
brutos_*do projetoigarape-datahub-dev - Tecnologia: DBT (Data Build Tool)
- Regras: Conformidade com Manual de Estilo do Instituto Igarapé
- Output: Tabelas dentro de conjuntos de dados com prefixo
tratada_*no mesmo projeto
A primeira atividade de transformação consiste em, para um dado conjunto de dados com prefixo brutos_, implementar o procedimento de padronização e validação de cada uma das tabelas. Como resultado, materializamos um novo conjunto de dados no projeto do Big query igarape-datahub-dev com o prefixo _tratada. Após esta etapa, um ponto muito importante entra em cena: A abertura de um Pull Request no repositório para que outro membro da equipe faça a correção dos processo aplicados
ETAPA 3: Revisão e Validação
Pull Request
Após implementar a transformação, é obrigatória a abertura de um Pull Request no repositório para revisão por outro membro da equipe técnica.
Itens verificados na revisão:
- Conformidade com Manual de Estilo
- Testes de validação executados com sucesso
- Documentação adequada do modelo
Transferência dos dados validados para o projeto datahub-igarape
Com o PR aprovado e mergeado, uma GitHub Action automaticamente:
- Executa os testes finais no ambiente de desenvolvimento
- Promove os dados para o projeto de produção
datahub-igarape - Materializa as tabelas com prefixo
validada_
ETAPA 4: Construção de análises e produtos de dados
Objetivo: Construir análises a partir dos dados validados e prontos para consumo
O mesmo conjunto de dados é materializado no projeto datahub-igarape com prefixo validada_. As tabelas desses conjuntos de dados já estão validadas, com o processo de tratamento devidamente registrado no repositório datalake-2025 e estão prontas para o uso na construção de anáises, outras tabelas e demais produtos de dados.
Com as tabelas validadas, os pesquisadores e cientístas de dados do Igarapé estão aptos a consumir os dados para criar seus produtos de dados.
Existem diversas formas de acesso aos dados, para análises exploratórias:
- Diretamente pela interface do Big Query
- Configurando o acesso com R
- Acessando os Dados com Python, usando o módulo pandasgbq
Durante o levantamento de requisitos do projeto, nos foi informado que o R é a ferramenta mais utilizada entre os futuros usuários do datahub. Por isso, será a principal ferramenta para construção de análises a partir dos dados.
-
O processo assume que a tabela que os pesquisadores/cientístas de dados subirão no projeto do Big Query datahub-igarape já está validada.
-
Nossa única restrição é que os scripts utilizados para gerar tabelas de análise sejam inseridos no repositório datalake-2025, de modo que o processo fique registrado no repositório de hospedagem dos códigos de coleta, tratamento e análise de dados.
-
Esta etapa pode ocorrer quantas vezes for necessário! É aqui que os dados validados ganham sentido.
ETAPA 5: Integração com aplicações
Baseando-se nas tabelas validadas, pesquisadores e cientistas de dados criam produtos analíticos especializados utilizando suas metodologias de pesquisa.
No manual de estilo, definimos um prefixo e um padrão de nomenclatura para identificar um produto de dados final que será utilizado em projetos do Igarapé. Por exemplo, o projeto de monitoramento de Risco. Os dados com prefixo projeto_ estão prontos para serem consumidos por aplicações reais!
Guia operacional de atualização dos dados
O processo de atualização engloba às etapas 1, 2 e 3 do fluxo de dados apresentado acima. Para facilitar sua execução disponibilizamos a seguir um guia operacional.
A atualização dos scrips já desenvolvidos geralmente envolve mudanças em:
a. Cobertura temporal: dados mais recentes que devem substituir os anteriores ou dados mais recentes a serem adicionados ao histórico já presente no BigQUery;
b. URL base ou URL de download;
c. Padrão no HTML das páginas acessadas para scraping.
Estas instruções buscam cobrir os casos a e b, uma vez que c envolve adaptações no código e inspeção mais detalhada dos HTMLs e requisições.
ETAPA 1: Alteração no arquivo constants.py
Acesse a pasta de código do dataset (NOME_DATASET) e procure por constants.py:
bash
cd models/$NOME_DATASET/code
No arquivo constants.py, procure por variáveis a serem atualizadas, tais como:
YEARouANO_INICIALeANO_FINAL: indicando o ano da cobertura temporal desejada;URL_BASEouURL_DOWNLOAD: indicando a url de onde são extraídos os dados;- Outras variáveis ligadas à fonte dos dados, mudanças no padrão das urls, mudanças na cobertura temporal, etc.
Atualize o que for necessário, assegure-se de que os links não estão quebrados e que existem de fato.
ETAPA 2: Rodar o script principal
Com as variáveis atualizadas e verificadas, salve o arquivo constants.py e use o uv para rodar o script de captura e tratamento dos dados:
📚 Nomenclatura de scripts
O script a ser rodado, geralmente tem o nome da tabela desejada:
Ex.: No dataset br_mapbiomas_cobertura_solo a tabela cobertura tem seus dados baixados e tratado no arquivo Python cobertura.py
bash
uv run script_principal.py
Erros de Conexão/Rede
Em alguns casos, pode ocorrer de o script falhar por timeout ou outro erro de conexão. Nesses casos, pode ser que aumentar o timeout no código do script ou mesmo rodá-lo novamente possa ser suficiente.
Esta etapa atualiza as tabelas brutas no BigQuery, através do upload dos dados em .parquet(particionados ou não) ou .csv no bucket do Google Cloud Storage. O método que geralmente é usado para tanto, é o load_to_datahub, do pacote. Caso seja necessário fazer adaptações, atente-se para o dataset_id correto, table_id correta e a localização certa do arquivo a ser enviado.
ETAPA 3: Materializar a tabela no BigQuery via DBT
Para que os dados brutos sejam materializados como tabelas tratadas, o seguinte comando deve ser executado:
bash
uv run dbt run --select nome_dataset__nome_tabela
ETAPA 4: Testar os dados
Depois de materializada a tabela tratada, é importante validar os dados, executando os testes dbt, por meio do comando:
bash
uv run dbt test --select nome_dataset__nome_tabela
ETAPA 5: Levar os dados para produção
Pull Request
Após implementar a atualização, é necessária a abertura de um Pull Request no repositório para revisão por outro membro da equipe técnica.
Itens verificados na revisão:
- Conformidade com Manual de Estilo
- Testes de validação executados com sucesso
- Documentação adequada do modelo
Transferência dos dados validados para o projeto datahub-igarape
Para que as atualizações sejam levadas para produção esse Pull Request deve conter:
- a tag: materialize-prod
- alguma alteração no arquivo .sql do modelo atualizado. É assim que a GitHub Action vai identificar quais dados devem ser atualizados em produção.
Com o PR aprovado e mergeado, uma GitHub Action automaticamente:
- Executa os testes finais no ambiente de desenvolvimento
- Promove os dados para o projeto de produção
datahub-igarape - Materializa as tabelas com prefixo
validada_